RStudio&RmdからVSCode&Quartoに移行した話 on Windows11
エディタはAtomを使っていたのですが、開発が終わってVSCodeに移行したのでRの環境もVSCodeに移行することにしましたので、導入手順のメモを残しておきます。
なお、日本語関係のトラブル回避のために、システムロケールをUTF-8に設定してます(一応、ベータとのことなので自己責任で・・・)

大まかな流れ
- Rのインストール
- TinyTeXのインストール
- VSCode対応のためのRのパッケージのインストール
- VSCodeのインストール
- フォントのインストール
- Quartoのインストール
- VSCodeの拡張機能のインストール
- VSCodeの設定
Rのインストール
https://cran.ism.ac.jp/ よりダウンロードしてインストール(執筆時点の最新版は4.2.2)
TinyTeXのインストール
Rを起動して
# TinyTeXパッケージのインストール install.packages("tinytex") # TinyTexのインストール tinytex::install_tinytex() # 日本語関係パッケージのためのリポジトリ設定 tinytex::tlmgr_repo("http://ftp.jaist.ac.jp/pub/CTAN/systems/texlive/tlnet/") # 日本語関係パッケージのインストール tinytex::tlmgr_install("collection-langjapanese")
VSCode対応のためのRのパッケージのインストール
install.packages("languageserver") install.packages("httpgd") install.packages("ragg")
Tidyverseのインストール
install.packages("tidyverse")
VSCodeのインストール
個人的にはディレクトリのコンテキストメニューに「Codeで開く」があると便利なので、チェックを入れとく。

フォントのインストール
お好みでどうぞ。この後のQuatoのPDF出力はNotoフォントの例を示してます。
- Noto Sans JP
- Noto Serif JP
- PlemolJP (VScode用)
Quartoのインストール
VSCode拡張機能のインストール
- R
- R Debugger
- Quarto
- vscode-icons
VSCodeの設定
Rの拡張機能の設定
- Use Httpgdにチェックを入れる
ショートカットでパイプの入力
コードチャンクのショートカット
[Ctrl] + [Shift] + [i] でコードチャンクの入力ができるが、RStudioと同じ([Ctrl] + [Alt] + [i])にしたい場合は以下のページを参考に設定する。
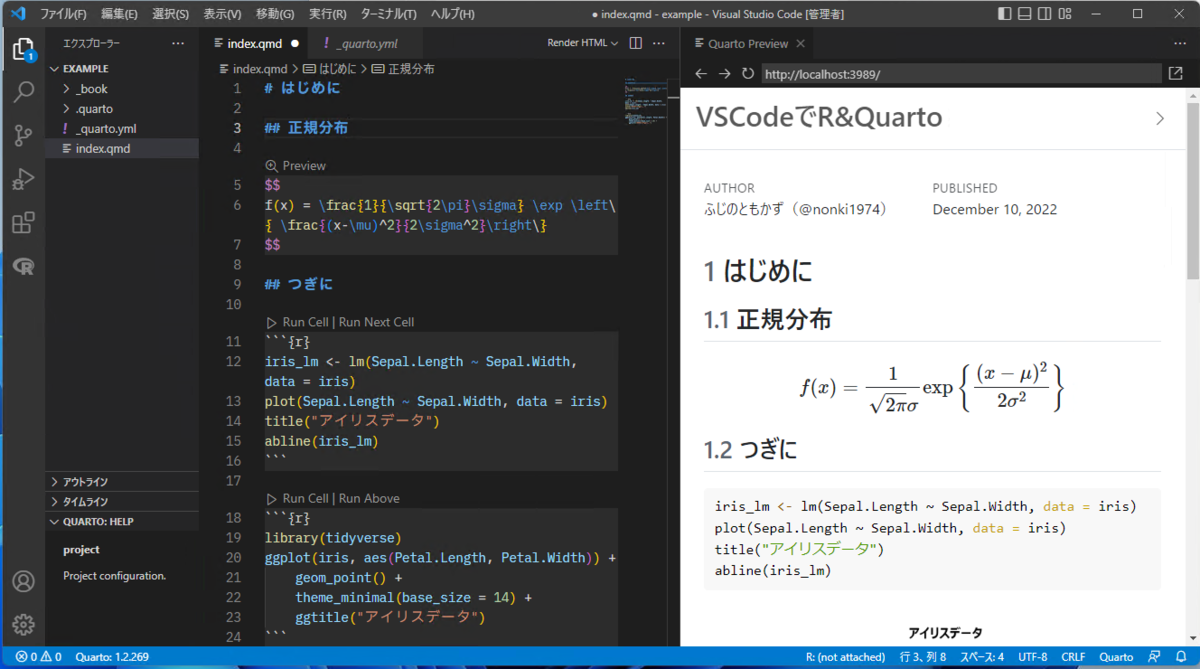
Quarto Bookの作成
_quarto.yml を以下の内容で作成する。PDFとHTML出力に対応。
index.qmd を以下の内容で作成する。章を追加する場合は新たに.qmdファイルを作成して、chaptersのところに追加する。
Render HTML & PDF
.qmdファイルの編集ウインドウの右上にある「Render HTML」もしくは「Render PDF」をクリックすると、HTMLやPDFへの変換が行われ、プレビューが表示される。

手書きのノートをスマホで撮影してPDFファイルを作成する方法
手書きのノートをスマホで撮影してPDFを作成し、送付やアップロードをする方法をここでは3つ紹介します。
- スマホの標準のカメラアプリを使う方法
- 【Androidのみ】Google Driveのアプリを使う方法(要Googleアカウント:Google Drive)
- Office Lensを使う方法(要Microsoftアカウント:One Drive)
2と3の方法は、クラウド上に保存されます。
スマホから直接メール送信や、各種Web上のシステムへアップロードもできると思いますが、ここでは、PCから送信もしくはアップロードするという前提で説明しています。
また、2と3の方法では、ノート以外の部分を自動的に削って(トリミング)くれます。
ノートとそれ以外の部分が明確に識別できるようなところで撮影すると
きれいにトリミングしてくれます。フローリングの床とかはきれいに判別してくれるようです。
スマホの標準のカメラアプリを使う方法
【Androidのみ】 Google Driveのアプリを使う方法(要Googleアカウント:Google Drive)
アプリをインストールしてない場合はインストールしておく。
Androidの場合はおそらくすでにインストールされれているはずです。
- Google Driveアプリを起動
- 右下の「+」をタップ
- スキャンをタップ
- ノートを撮影する
- 保存をタップ
- 続きのページがある場合は左下の「+」をタップして、4の手順に戻る。ない場合は「保存」をタップ
- ファイル名を入力して、「保存」をタップ
- Google DriveにPDFファイルができているので、PCからGoogle Driveにアクセスして、PDFファイルをPCにダウンロードしてからファイルを送信orアップロード
Office Lensを使う方法(要Microsoftアカウント:One Drive)
アプリをインストールしてない場合はインストールしておく。
- Office Lensアプリを起動
- ノートを撮影する
- 続きのページがある場合は左下の「新しく追加」をタップして、2の手順に戻る。ない場合は「完了」をタップ
- ファイル名を入力する
- 「PDF」のところにチェックを入れて「保存」をタップ
- One DriveにPDFファイルができているので、PCからOne Driveにアクセスして、PDFファイルをPCにダウンロードしてからファイルを送信orアップロード
TinyTeXのインストール & RmarkdownでPDF on Windows10
以前の記事 nonki1974.hateblo.jp の内容をWindows10でやってみた記録。
環境
- Windows10 1909
TinyTeXのインストール&Atomで編集&タイプセットまで
Atomのインストール
https://atom.io/ からダウンロード&インストール
以下のパッケージをインストール
Perlのインストール
AtomでのTeXのタイプセット時にlatexmkを使うので必要。以下のサイトよりインストールしておく。 Strawberry Perl for Windows
TinyTeXのインストール
https://github.com/yihui/tinytex/tree/master/tools から install-windows.batをダウンロード&実行
TeXの日本語環境をインストール
# リポジトリの設定 tlmgr option repository http://ftp.jaist.ac.jp/pub/CTAN/systems/texlive/tlnet/ # collection-langjapaneseのインストール tlmgr install collection-langjapanese
uplatexの設定時にエラー(hyph-de-1901.ec.texがない)が出ていたので調べてみると、hyph-utf8パッケージの一部ファイルが正常に入っていなかった。githubのリポジトリからhyph-utf8以下のファイルをとってきて%APPDATA%\TinyTex\texmf-dist\tex\generic\hyph-utf8にコピーしたらうまくいった。
フォントのインストール
から「OpenType/CFF Collection (OTC)」のところを全部ダウンロードしてきてインストール。 ただし、「すべてのユーザーに対してインストール」すること。
Atomの設定とタイプセットのテスト
Atomのlatexパッケージの設定でEngineをuplatexにする。
\documentclass[a4j, uplatex]{jsarticle} \usepackage[noto-otc]{pxchfon} \begin{document} \section{はじめに} $X \sim N(\mu, \sigma^2)$の{\bf 確率密度関数}は \[ f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\} \] である。 \end{document}
完成!

RのインストールからknitrでPDF出力まで
RとRStudioのインストール
Rmdファイルの作成
---
title: "TinyTeXを使ってみよう"
author: "nonki1974"
date: "2020年2月19日"
output:
pdf_document:
latex_engine: xelatex
documentclass: bxjsarticle
classoption: xelatex, ja=standard, base=12pt
header-includes:
- \usepackage{zxjatype}
- \setjamainfont{Noto Serif CJK JP}
- \setjamonofont{Noto Sans Mono CJK JP}
- \setjasansfont{Noto Sans CJK JP Medium}
- \setmainfont{Noto Serif CJK JP}
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
knitr::opts_chunk$set(dev="cairo_pdf",
dev.args=list(family="Noto Sans CJK JP Medium"))
```
## R Markdownのテスト
`pressure`データのプロットです。
```{r fig.height=4}
plot(pressure, xlab = "温度[℃]", ylab = "蒸気圧[mm]")
```
knitする
できた!

ENJOY!!
TreeTaggerをkoRpusパッケージでRから使う(on Windows)
多言語対応の形態素解析ツールTreeTaggerをRから使う場合のメモ。英語で使う場合。
1. TreeTaggerのインストール
- TreeTaggerのページからzip圧縮されたWindows向けのバイナリを「for Windows64」もしくは「for Windows32」のリンクからダウンロード。執筆当時の64bit版の最新版。
- 展開してできるフォルダをC:\の直下に移動(任意のフォルダでOKだが、その場合はバッチファイルの設定変更が多分必要)
- TreeTaggerのページからパラメータファイルを「English parameter file (PENN tagset) 」のリンクからダウンロード。執筆当時の最新版。
- gz形式で圧縮されているので、7zipやWinzipなどのツールで展開。出てきたファイルenglish.parをC:\TreeTagger\libに移動。
3. 動作確認
コマンドプロンプトを起動して
cd C:\TreeTagger\bin .\tag-english ..\INSTALL.txt
でインストールの説明ファイルの形態素解析結果が出てくればOK
4. koRpusの導入と実行
Rを起動して
# koRpusパッケージのインストール install.packages("koRpus")
多くのサイトでこれだけで実行できると書いているが、英語対応のためののパッケージkoRpus.lang.enを入れないとダメでした。(前にLinuxでやったときは不要だったような気がしましたが、最近変更になったのか、Windowsだけの話なのかは確認してないので不明)
install.packages("koRpus.lang.en")
これをロードすると依存パッケージのkoRpusも読み込まれる。
library(koRpus.lang.en)
TreeTaggerの実行ファイルを指定
set.kRp.env(TT.cmd = "C:\\TreeTagger\\bin\\tag-english.bat", lang = "en")
もしくは
set.kRp.env(TT.cmd = file.choose(), lang = "en")
でファイル選択でOK。
作業ディレクトリに適当なテキストファイル(ここではtest.txt)を作っといて
taggedText(treetag("test.txt"))
で実行。
recogeoパッケージで市町村合併に伴う再集計をやってみる
市区町村単位で集計された統計データで時点間の比較をしようとすると、市町村合併によって2時点間で地域の対応が取れないことがあります。必要に応じて自前でスクリプトを書いて対応していますが、よさげなパッケージ(recogeo package)がリリースされていたのでちょっと試してみました。
2005年と2010年の国勢調査で得られた福岡県の人口データを例にやってみます。データは統計GISの小地域境界データのShapeファイルを使います。
パッケージのロード
library(tidyverse) library(sf) library(rmapshaper)
2005年データのダウンロードと展開
url2005 <- "https://www.e-stat.go.jp/gis/statmap-search/data?dlserveyId=A002005212005&code=40&coordSys=1&format=shape&downloadType=5" tf <- tempfile() curl::curl_download(url2005, tf) unzip(tf, exdir = "pop2005", junkpaths = TRUE) unlink(tf) rm(tf)
2005年データの読み込み
st_read()でシェープファイルを読み込む。海域のポリゴンを除去するために、HCODE == 8101で町丁・字等に限定。rmapshaper::ms_dissolve()で市区町村単位でディゾルブ。市区町村コードをPREFとCITYを結合して作成。rmapshaper::ms_simplify()でジオメトリを簡素化。rmapshaper::ms_filter_islands()で面積の小さい離島を除去。
pop2005 <- st_read("./pop2005", options = "ENCODING=CP932", stringsAsFactors = FALSE) %>% filter(HCODE == 8101) %>% select(PREF, CITY, CITY_NAME, JINKO, SETAI) %>% ms_dissolve("CITY_NAME", sum_fields = c("JINKO", "SETAI"), copy_fields = c("PREF", "CITY")) %>% mutate(CITY_CODE = str_c(PREF, CITY)) %>% select(-PREF, -CITY) %>% ms_simplify() %>% ms_filter_islands(min_area = 2000000) %>% rename(JINKO2005 = JINKO, SETAI2005 = SETAI) %>% st_set_crs(pop2005, 4612) %>% st_transform(2444)
2010年も同様に
url2010 <- "https://www.e-stat.go.jp/gis/statmap-search/data?dlserveyId=A002005212010&code=40&coordSys=1&format=shape&downloadType=5" tf <- tempfile() curl::curl_download(url2010, tf) unzip(tf, exdir = "pop2010", junkpaths = TRUE) unlink(tf) rm(tf) pop2010 <- st_read("./pop2010", options = "ENCODING=CP932", stringsAsFactors = FALSE) %>% filter(HCODE == 8101) %>% select(PREF, CITY, CITY_NAME, JINKO, SETAI) %>% ms_dissolve("CITY_NAME", sum_fields = c("JINKO", "SETAI"), copy_fields = c("PREF", "CITY")) %>% mutate(CITY_CODE = str_c(PREF, CITY)) %>% select(-PREF, -CITY) %>% ms_simplify() %>% ms_filter_islands(min_area = 2000000) %>% rename(JINKO2010 = JINKO, SETAI2010 = SETAI) %>% st_set_crs(pop2005, 4612) %>% st_transform(2444)
地図の描画
市区町村数は市町村合併により、97から72に減少しています。
nrow(pop2005) ## [1] 97 nrow(pop2010) ## [1] 72
geom_sf()で地図の描画。
gridExtra::grid.arrange( ggplot(pop2005) + geom_sf(aes(fill = log(JINKO2005)), lwd = 0.2) + scale_fill_gradient(low="white", high="red"), ggplot(pop2010) + geom_sf(aes(fill = log(JINKO2010)), lwd = 0.2) + scale_fill_gradient(low="white", high="red"), ncol = 2)

recogeoパッケージを使う
ここからやっと本題。recogeo::reconcileGeographies()関数を使うと、2つの空間オブジェクトに含まれるポリゴン同士の関係(同じsame / 含むcontains / 重なるintersects)の判定をしてくれます。ただ、実際にはこれらの判定がそのままではうまくいかないことがあります。例えば、若松区(40103)の場合、
pop2005.wakamatsu <- pop2005 %>% filter(CITY_NAME == "若松区") pop2010.wakamatsu <- pop2010 %>% filter(CITY_NAME == "若松区") ggplot() + geom_sf(data = pop2005.wakamatsu, color = "red", fill = NA) + geom_sf(data = pop2010.wakamatsu, color = "blue", fill = NA)

このように微妙にずれていますので、実際には同じ自治体なのですが、いずれも包含関係になりません。
そこで片方について、500mバッファをとってみます。
ggplot() + geom_sf(data = pop2005.wakamatsu, color = "red", fill = NA) + geom_sf(data = st_buffer(pop2010.wakamatsu, 500), color = "blue", fill = NA)

これなら確実に2010年のポリゴンで2005年のポリゴンを含むことができます。逆も同様に実行した場合に、包含関係が成立すれば、2つのポリゴンは同一自治体のものと判定するという感じになっている(と推測してます)。一方の包含関係のみが成立する場合はcontainになって、今回のデータの場合は、合併があったことを示すものになります。
次に、intersectについてですが、そのままintersectかどうかのチェックをすると、多くの隣接自治体がintersectと判定されてしまいます。2005年の若松区は2010年の若松区と芦屋町と八幡西区とintersectの関係にあると判定されます。
st_intersects(pop2005.wakamatsu, pop2010) ## 1: 3, 8, 49 ggplot() + geom_sf(data = pop2010[c(3, 8, 49),], color = "blue", fill = NA) + geom_sf(data = pop2010.wakamatsu, color = "red", fill = NA)

これを抑止するために、intersectしたときの共通部分の面積が、一定以上の値でないと、intersectしているとみなさないということにします。今回のデータでは合併のみしか起こっていませんので、intersectの判定は生じないはずです。つまり、intersectが出現しないように、その閾値を設定すればよいことになります。
実際の判定に、recogeo::reconcileGeographies()関数を使います。
devtools::install_github('fraba/recogeo') library(recogeo) pop_recogeo <- reconcileGeographies( pop2010, pop2005, "CITY_CODE", "CITY_CODE", dist_buffer = 500, min_inters_area = 30000)
これで、pop_recogeoにこの期間での合併情報がdata.frameの形式で格納されます。以下は、一部の出力ですが、2006年にあった飯塚市(40205)と周辺の4自治体の合併情報が確認できます。
pop_recogeo %>% arrange(unigeokey_A) %>% slice(18:24) ## unigeokey_A unigeokey_B type ## 1 40205 40205 AcontainsB ## 2 40205 40425 AcontainsB ## 3 40205 40426 AcontainsB ## 4 40205 40427 AcontainsB ## 5 40205 40428 AcontainsB ## 6 40206 40206 same ## 7 40207 40207 same
この情報を使って、recogeo::reconcileData()関数で人口と世帯数の集計をしてみます。
pop_recodat <- reconcileData(pop_recogeo, pop2010, pop2005, "CITY_CODE", "CITY_CODE", varA = c("JINKO2010", "SETAI2010"), varB = c("JINKO2005", "SETAI2005"), return_spatial = "A") pop_recodat %>% as_tibble() %>% select(1:5) %>% slice(1:5) ## # A tibble: 5 x 5 ## .unigeokey_new JINKO2010 SETAI2010 JINKO2005 SETAI2005 ## <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 104469 44232 108677 44364 ## 2 2 85167 33495 87340 32754 ## 3 3 61583 28064 63714 28417 ## 4 4 181936 89036 183286 87459 ## 5 5 214793 86420 214624 83716
2010年の行政区域で2005年の人口と世帯数が再集計されています。 これで、世帯当たりの人数を地図上に可視化してみると次のようになります。
pop_recodat %>% mutate(`2010` = JINKO2010 / SETAI2010, `2005` = JINKO2005 / SETAI2005) %>% select(`2005`, `2010`) %>% gather(year, n_household, `2005`, `2010`) %>% ggplot(aes(fill = n_household)) + geom_sf() + facet_wrap(.~year) + scale_fill_gradient(low="white", high="red")

とりあえず、合併のみという単純な場合なら使えそうな感じです。政令指定都市への移行などで生じる分割や、もっと複雑な場合もありますが、その検証はまた別の機会に。
Enjoy!
TinyTeXのインストール & RmarkdownでPDF on Ubuntu 18.04 LTS
TinyTex のインストール
Motivation
TeXのインストールはヘビーなので、なるべく簡素化したい。TeX Liveとか数GBをダウンロードせんといかん。
環境
Atomのインストール
sudo add-apt-repository -n -y ppa:webupd8team/atom sudo apt update sudo apt install atom
パッケージのインストール
apm install japanese-menu latex language-latex latexer pdf-view
TinyTexのインストール
wget -qO- "https://yihui.name/gh/tinytex/tools/install-unx.sh" | sh
TinyTeXのインストール(for R users)
すでにRが入っていれば、以下でOK。
install.packages('tinytex') tinytex::install_tinytex()
PATHの設定
export PATH=$HOME/.TinyTeX/bin/x86_64-linux:$PATH
.bashrcに追加しとく
TeXの日本語環境をインストール
# リポジトリの設定 tlmgr option repository http://ftp.jaist.ac.jp/pub/CTAN/systems/texlive/tlnet/ # collection-langjapaneseのインストール tlmgr install collection-langjapanese
Notoフォントの設定
Ubuntuの日本語言語パックでNotoフォントが/usr/share/fonts/opentype/notoに入っているので、それを使う。入っていない場合はインストールする。
mkdir texmf-local cd texmf-local mkdir fonts cd fonts ln -s /usr/share/fonts/opentype/ opentype mktexlsr
Atomの設定とタイプセットのテスト
Atomのlatexパッケージの設定でEngineをuplatexにする。
\documentclass[a4j, uplatex]{jsarticle} \usepackage[noto-otc]{pxchfon} \begin{document} \section{はじめに} $X \sim N(\mu, \sigma^2)$の{\bf 確率密度関数}は \[ f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left\{-\frac{(x-\mu)^2}{2\sigma^2}\right\} \] である。 \end{document}
完成!

knitrでPDF出力
この流れでRmarkdownからpdf-documentとかbeamer presentationの作成までやってしまいたい。
Rのインストール
/etc/apt/sources.listに以下を追加
deb https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/
キーの登録、パッケージリスト更新、インストール
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9 sudo apt update sudo apt install r-base r-base-dev
RStudioのインストール
wget https://download1.rstudio.org/rstudio-xenial-1.1.463-amd64.deb sudo apt install gdebi-core sudo gdebi rstudio-xenial-1.1.463-amd64.deb
IPAexフォント入れとく
sudo apt install fonts-ipaexfont
Rmdファイルの作成
---
title: "TinyTeXを使ってみよう"
author: "nonki1974"
date: "2018年12月26日"
output:
pdf_document:
latex_engine: xelatex
documentclass: bxjsarticle
classoption: xelatex, ja=standard
geometry: no
header-includes:
- \usepackage{zxjatype}
- \setjamainfont{Noto Serif CJK JP}
- \setjamonofont{Noto Sans Mono CJK JP}
- \setjasansfont{Noto Sans CJK JP Medium}
- \setmainfont{Noto Serif CJK JP}
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
knitr::opts_chunk$set(dev="cairo_pdf",
dev.args=list(family="Noto Sans CJK JP"))
```
## R Markdownのテスト
`pressure`データのプロットです。
```{r}
plot(pressure, xlab = "温度[℃]", ylab = "蒸気圧[mm]")
```
knitする
できた〜

宿題
Windowsでも動作確認
sfパッケージ&国土数値情報でコロプレス図
Rで地図を描画する際はspパッケージが必須だったわけですが、今後sfパッケージの方が便利にになるらしいです。dplyrと相性がいいんでしょうね。この本でやっている、ごみ排出量のコロプレス図の作成をsfパッケージでやってみることにします。
シェープファイルの取得
国土数値情報からシェープファイルをダウンロード。kokudocuuchiパッケージを使って、URLを確認。
library(dplyr) kokudosuuchi::getKSJSummary() %>% filter(title=="行政区域")
## # A tibble: 1 x 5 ## identifier title field1 field2 areaType ## <chr> <chr> <chr> <chr> <chr> ## 1 N03 行政区域 政策区域 - 3
ということなので、福岡県(prefCode = 40)を指定してURL一覧を取得。そこから2015年のもののみ取り出す。
kokudosuuchi::getKSJURL("N03", prefCode = 40) %>% filter(year==2015) %>% select(zipFileUrl) %>% pull(1) -> url
ファイルをダウンロードしてカレントディレクトリに展開。
tf <- tempfile() curl::curl_download(url, tf) unzip(tf, exdir = getwd(), junkpaths = TRUE) unlink(tf) rm(tf)
シェープファイルの読み込み→加工→白地図の描画
sfパッケージをロードして、シェープファイルを読み込む。
library(sf) d <- st_read(".", options = "ENCODING=CP932", stringsAsFactors = FALSE)
政令指定都市については、ごみ排出量のデータは、全体での集計になっているのに対して、シェープファイルは区ごとのデータになっているため、政令指定都市全体をaggregate()関数を使って1つのポリゴンにまとめる。まとめた後に、市区町村名(N03_004)と、市区町村コード(N03_007)の修正が必要。
d %>% filter(N03_003 %in% c("北九州市","福岡市")) %>% aggregate(by = list(.$N03_003), FUN = "head", n=1) %>% select(-1) %>% mutate(N03_004 = N03_003, N03_007 = case_when(N03_004 == "北九州市" ~ "40100", N03_004 == "福岡市" ~ "40130")) -> d.seirei
他の市区町村についても、国土数値情報のデータは1つの市町村が多くのポリゴンの集まりになっているので、これらも1つのポリゴンにまとめる。
d %>% filter(!(N03_003 %in% c("北九州市", "福岡市"))) %>% aggregate(by = list(.$N03_007), FUN = "head", n=1) %>% select(-1) -> d.others
これらをまとめる。
rbind(d.seirei, d.others) %>% arrange(N03_007) -> d.new
白地図を出力。
plot(st_geometry(d.new), border="grey", col="white")

ごみ排出量データの取得と、sfオブジェクトへのマージ
ダウンロードするファイルのURLと保存先ファイル名の指定。e-statのAPI使ってやると便利かもしれないけど、idの取得が必要になるので今回はパス。
waste_url <- "http://www.env.go.jp/recycle/waste_tech/ippan/h27/data/shori/city/40/01.xls" waste_fn <- "waste_fuk_h27.xls"
ダウンロードして、readxlパッケージでExcelのファイルを読み込む。列名を設定して、特に使う項目は分かりやすい列名に変更。
curl::curl_download(waste_url, waste_fn) waste_fuk <- readxl::read_excel(waste_fn, sheet = 1, skip = 6) colnames(waste_fuk) <- paste0("V", seq(1:ncol(waste_fuk))) waste_fuk %>% rename(jcode=V2, name=V3, waste_total=V12) -> waste_fuk
sfオブジェクトへマージ。
left_join(d.new, waste_fuk, by = c("N03_007" = "jcode")) -> d.new2
コロプレス図(塗り分け地図)の作成。
library(classInt) library(RColorBrewer) ci <- classIntervals(d.new2$waste_total, style = "pretty") d.new2 %>% select(waste_total) %>% plot(col=findColours(ci, rev(brewer.pal(7, "RdYlGn"))))

ggplot2のgeom_sf()を使った地図の描画
開発版のggplot2では、geom_sf()を使って、sfオブジェクトからggplot2形式のプロットが作成できます。 Windowsの場合は開発ツールをインストールしてから、以下のようにすればインストールできます。
devtools::dev_mode() devtools::install_github("hadley/scales") devtools::install_github("tidyverse/ggplot2")
library(ggplot2) ggplot(d.new2, aes(fill=waste_total)) + geom_sf() + scale_fill_distiller(palette="RdYlGn") + theme_bw()

enjoy!